개요
- LLM을 직접 구현해보면서 심층적인 이해를 도모하는 그룹 스터디에 참석해서 학습을 시작했다.
- 총 5회, 주차별 미팅때 함께 논의할 파트를 미리 정해두기는 하지만 기본적으로 자기주도적 학습(self-paced) 형태로 학습하였다.
학습 일정
250302 ~ 250330. 매주 일요일 2시간. 5회
학습한 내용
LLM(Large Language Model)
대규모 언어 모델
거대한 데이터를 어떤 방법으로 학습시키고 어떻게 생성하느냐

Building & Using LLM
우리가 쓰는 LLM은 아래와 같이 만들고 사용되어 진다.

Transformer Architecture
이 아키텍쳐가 나오기 전에는 RNN (Recurrent Neural Networks), LSTM (Long Short-Term Memory) 같은 형태의 아키텍쳐를 사용했다고 한다. 그러나, 문제가 병렬처리가 어렵거나 연산량이 너무 많은 문제점이 있었다고 한다.
그 외에도 여러가지가 많지만, 차츰 발전되어 오다가 Attention 메커니즘 이라는 걸 고안해내었다. 중요한 정보에 가중치를 부여해서 문맥을 더 잘 이해할 수 있도록 한 것이다.
Transformer 아키텍쳐는 2017년에 등장했고, Self-Attention 메커니즘과 병렬 연산 덕분에 지난 방식들의 단점을 극복하고 현재 우리가 사용하게 된 것이다. 아무래도 병렬로 처리하다보니, GPU의 특성이 매우 잘 고려되었던 듯. 그러고보니, 예전에 어떤 개발자가 GPU를 이용해서 이 아키텍쳐를 돌렸더니, 엄청 효과가 좋아서 센세이션 했던 기억이 난다.


BERT & GPT
BERT, GPT 두 모델의 차이를 아래 이미지를 통해보면 바로 알 수 있다.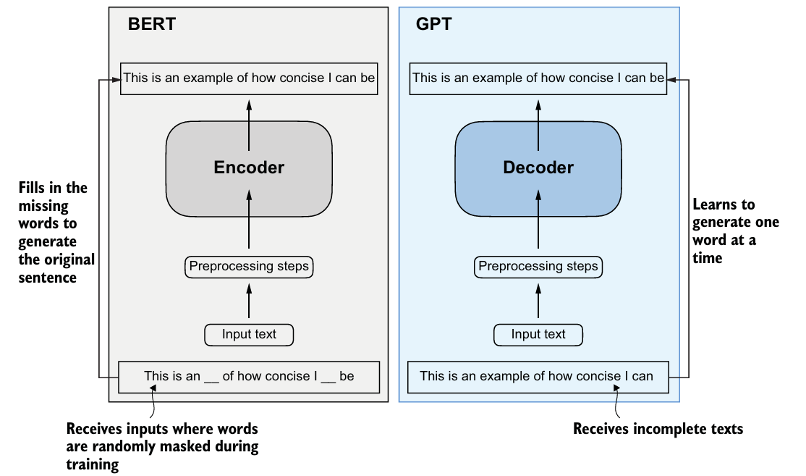
GPT 동작원리
GPT 동작원리도 꽤 재밌는데, Iteration 형태로 하나씩 추적하는 형태이다. 사전에 학습만 병렬로 하지, 처리자체는 순차적 처리를 한다. 그래서 GPT에서도 답변이 그렇게 순차적으로 나오는 것이다. 이렇게 나오기 위해서 뒤에 단어들을 모두 마스킹하고 답을 요구하는 기술도 적용되고 그러하다. 일단 순차적으로 추측 시에, 학습된 모델에서 후보군 중 가중치가 높은 것을 선택하고, 만들어진 문장에서 후보군을 학습모델에서 도출하고 가중치가 높은 것을 선택하는 것의 반복으로 문장이 만들어진다고 보면 된다. (이 부분이 꽤 재밌었다. 😃)
*이 지식 군단에서는 단어 나열 뭉치를 Token으로 부르고 있었다. 단어 덩어리나 문장까지도 토큰이 될 수 있어서 걍 애매하게 사용하는 것 같다.

Attention Mechanisms
주의 메커니즘 이라는 거를 3장부터 이야기하는데, 학습된 모델에서 추천된 후보군 중 가중치가 높은 것을 선택하고 성능을 향상해 나가는 역할을 하게 되는 개념이자 기능이다.
self-attention 이라는 것도 있는데, 행렬 연산으로 계속 병렬로 연산을 해나가면서 스스로의 성능을 향상해나가는 개념이다.
그 외에도 causal (커즐?) atention 이라는 것도 있었는데, 아까 말했던 미래의 토큰은 참조를 못하도록 마스킹 적용하는 방법을 말한다.

GPT는 위와 같은 비교표를 내놓더라.
dropout 이라는 것도 알게 되었는데, 이는 학습이 편향되지 않도록 drop을 의도적으로 하는 것을 의미한다. 그러나, 어느정도의 편향을 만들어서 모델별 개성을 만들어 내는 것도 꽤 중요하다. 글쓰기에 집중된 모델, 코드 생성에 집중된 모델 등... 그러하다.
multi-head attention 이라는 것은 self-attention을 병렬로 하는 것이다.
Layer Normalization 이라는 것은 딥러닝의 각 층별로 출력 데이터를 비슷하게 출력하게 끔 일반화 하는 행위를 말한다. 근데 최근 논문에서는 걍 Tanh 함수를 이용해서 출력범위를 -1~1 사이 값으로 강제로 조정하는게 특별하게 Normalize 하는 것보다 효과가 좋다고 한다ㅋㅋㅋㅋ (초기라 그런지 모두 물먹는 게 일단위 주단위로 일어나는 중... 출처 : https://arxiv.org/pdf/2503.10622 / 논문 제목 : Transformers without Normalization)
Layer Normalization 덕분에 학습 안정성이 향상되었다고 하는데, 오히려 빼는 게 더 좋았었다니, 생각과 현실은 늘 다른듯.
Transformer 아키텍쳐가 적용된 학습 블록들이 모여서 GPT 같은 것을 만들게 되는데, 가중치의 학습이 어떻게 되어 있는가가 꽤 주요한 요소가 되긴 한다.
GPT 모델의 파라미터 수가 많다고 좋을 거는 없다고 한다. 실제 gpt 4o mini 같은 거 보면, 더 빠르고 좋은 부분이 분명히 존재하니까...
남은 과제
5주차에 이걸 해볼 생각이다.
- 직접 LLM 로컬환경에 프로그래밍으로 구축해보기